TL;DR
Token pruning has so far been explored only for 2D VLMs. We analyze the redundancy of projection-based
3D VLM tokens and propose 3DZip — the first training-free, geometry-aware token compression for 3D VLMs.
Abstract
Abstract
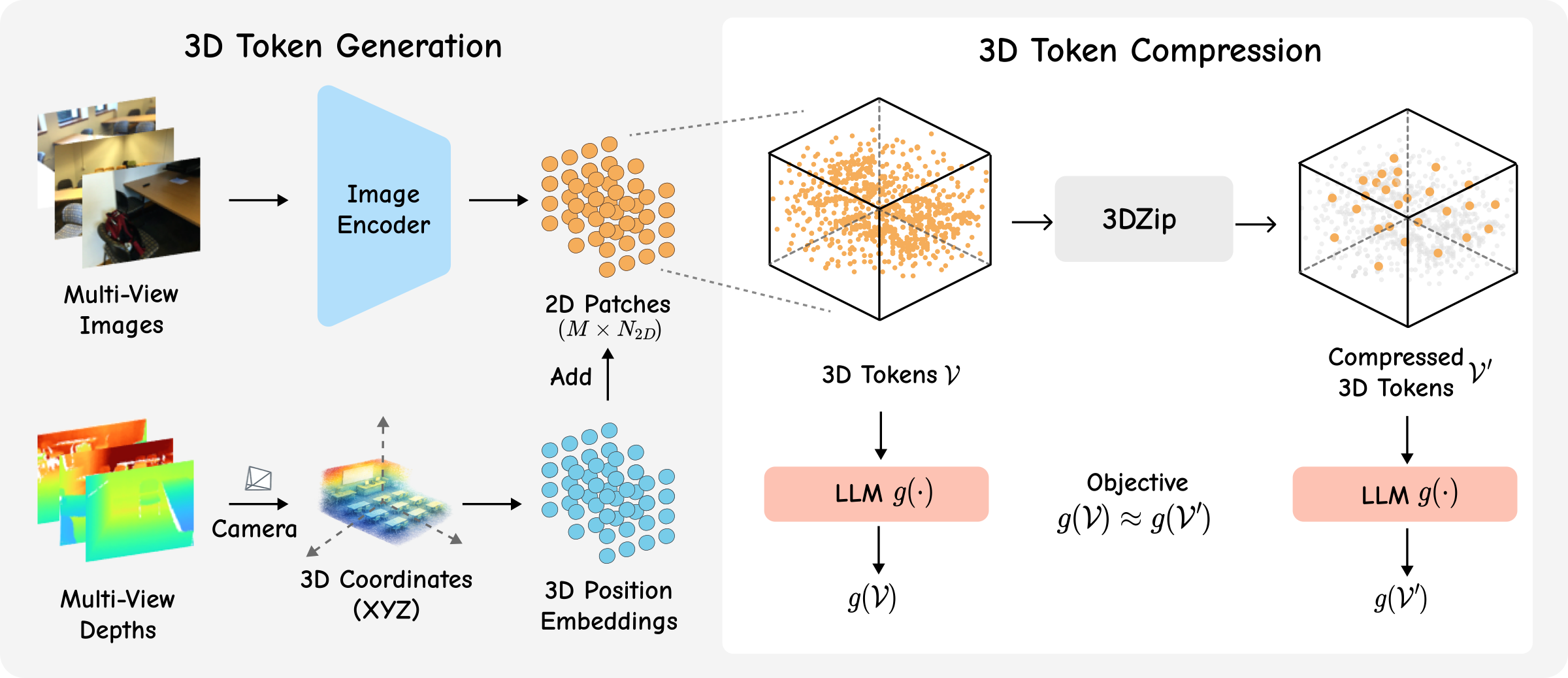
Recent 3D vision-language models (3D VLMs) construct geometry-aware tokens by projecting 2D visual features
into world coordinates, enabling spatial reasoning for tasks such as 3D question answering. However, this
design generates thousands of tokens per scene, resulting in substantial computational and memory overhead.
While token compression has been extensively studied in 2D VLMs, existing approaches rely on semantic
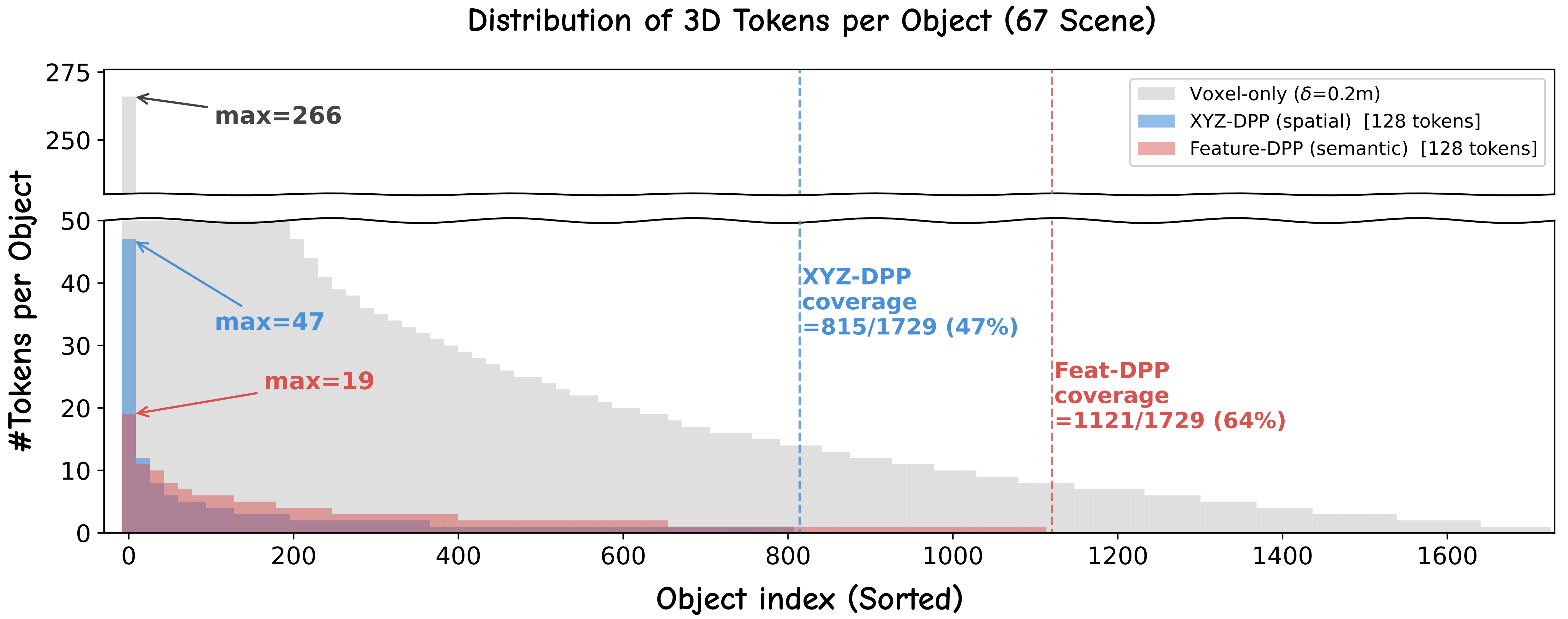
relevance or attention-based selection that overlook the structured spatial nature of 3D tokens. Moreover,
redundancy in 3D representations cannot be resolved by spatial proximity alone, as object-level token
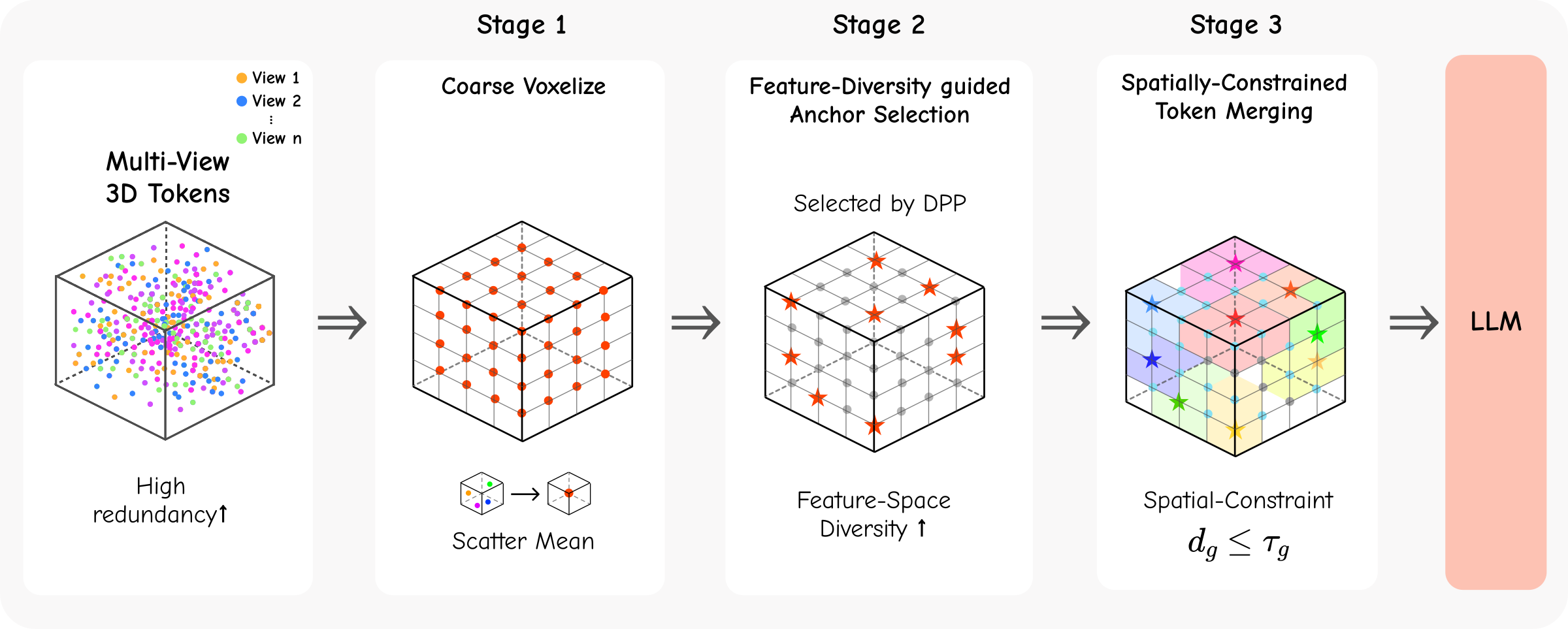
imbalance persists even after spatial aggregation. To address this, we propose 3DZip, a three-stage
token compression framework that first applies coarse voxelization to remove point-level redundancy,
then selects anchor tokens based on feature-space diversity via a Determinantal Point Process, and
finally merges remaining tokens under spatial constraints to preserve geometric coherence. Experiments
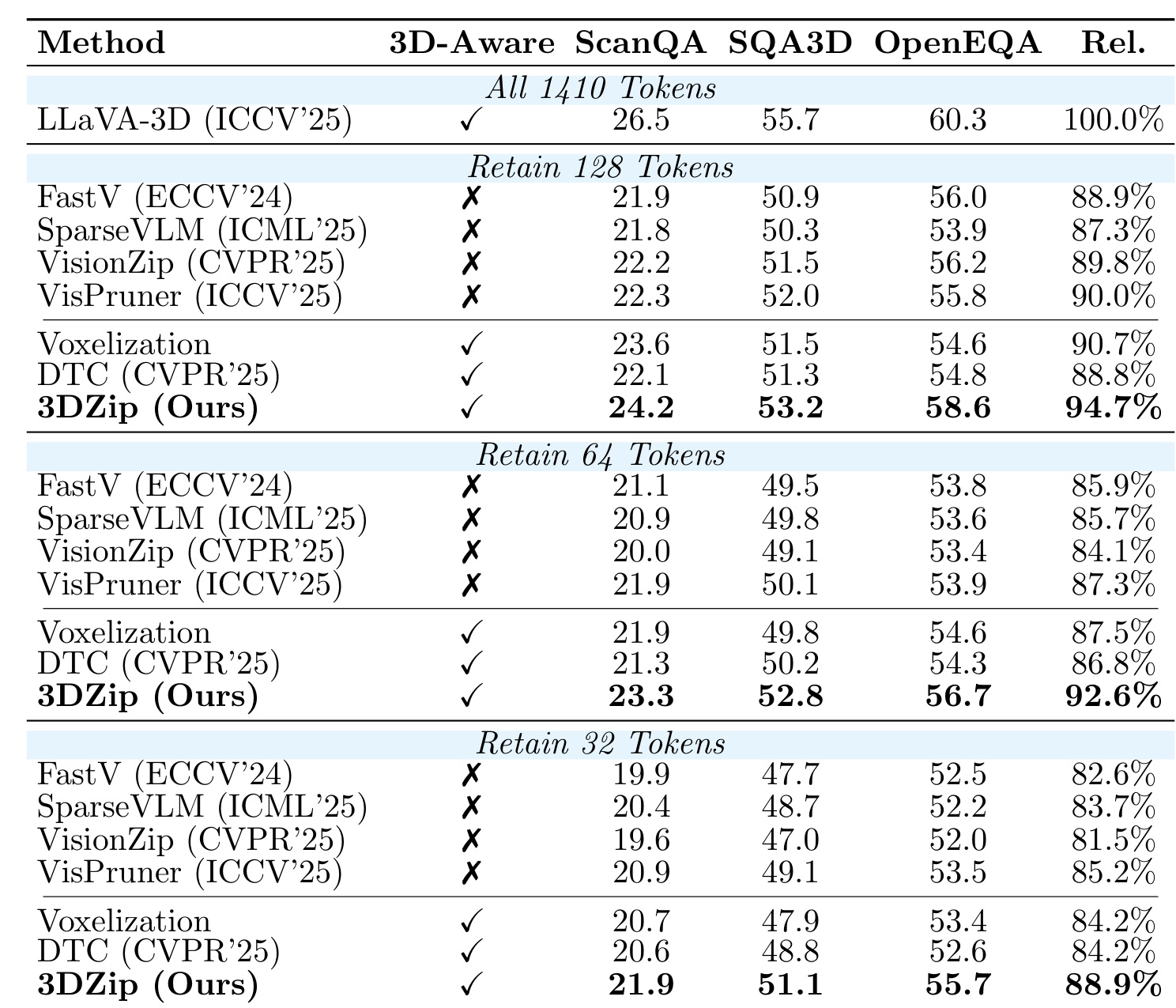
on three 3D question answering benchmarks demonstrate that 3DZip consistently outperforms existing
compression methods, retaining 94.7% of the original performance with only 128 tokens, achieving a 1.92×
faster inference speed.